Section outline
-
-
-
平时作业70分。(明年将恢复到本门课设置的初衷,编程作业降低回60分)。作业0到作业8,作业0,10分;后8次作业每次满分15分(有的有pdf手写题目作业5分,编程10分;如果只有编程则15分),超过70分按70分计算,不接受补交,因为每次deadline为下次上课前,上课大课间将对本次作业进行讲解。代码补全作业(提供了基础starter代码的作业)禁止复制粘贴任何代码。其他作业允许使用网上代码,禁止使用(复制粘贴)同学他人作业代码,请同时提交readme文件具体说明使用网上代码的情况。
完成书面综述报告5分。写法按小论文related work写法(中英文均可,要有类似however段落进行批判性总结分析)。
完成批判性口头报告(每位参与者将通过一到两篇代表性科学论文对一个研究主题进行详细研究。参与者将在约 30 分钟的演讲中介绍论文的主要思想。目标是其他参与者在演讲后理解报告人对两篇论文的批判性分析。)15分,可做多次取最高分。
完成对批判点的改进实验,10分。
总计100分。
报告 和 review模版 请大家注意 按此总结 多数情况下阅读的重点是:
A、文章讨论的核心问题是什么?一般不超过三个,会在abstract和introduction里强调出来。在related work文章是怎么评价相关工作存在的问题的。
B、各个核心问题的解法是什么?做了什么假设?
先看摘要,再看Introduction知道文章想要讨论的问题/现象,然后直接跳到最后的总结,然后跳到关键例子。这是一种“输入”型的阅读法。如果你的阅读目的是想为作者处理过的核心问题提出新的解法,想要“输出”,那这时还要加上:
C、各核心假设是基于什么样的证据和动因,论证是否充分?消融实验是否充分?
D、解法里使用了什么样的技术,用得对不对?
E、核心理论有什么样的prediction
基本要实现看完就能写review section的程度。
-
-
-
Students mustMark as done
-
Students mustMark as done

-
Students mustMark as done
-
-
Students mustMark as done
-
Students mustMark as done
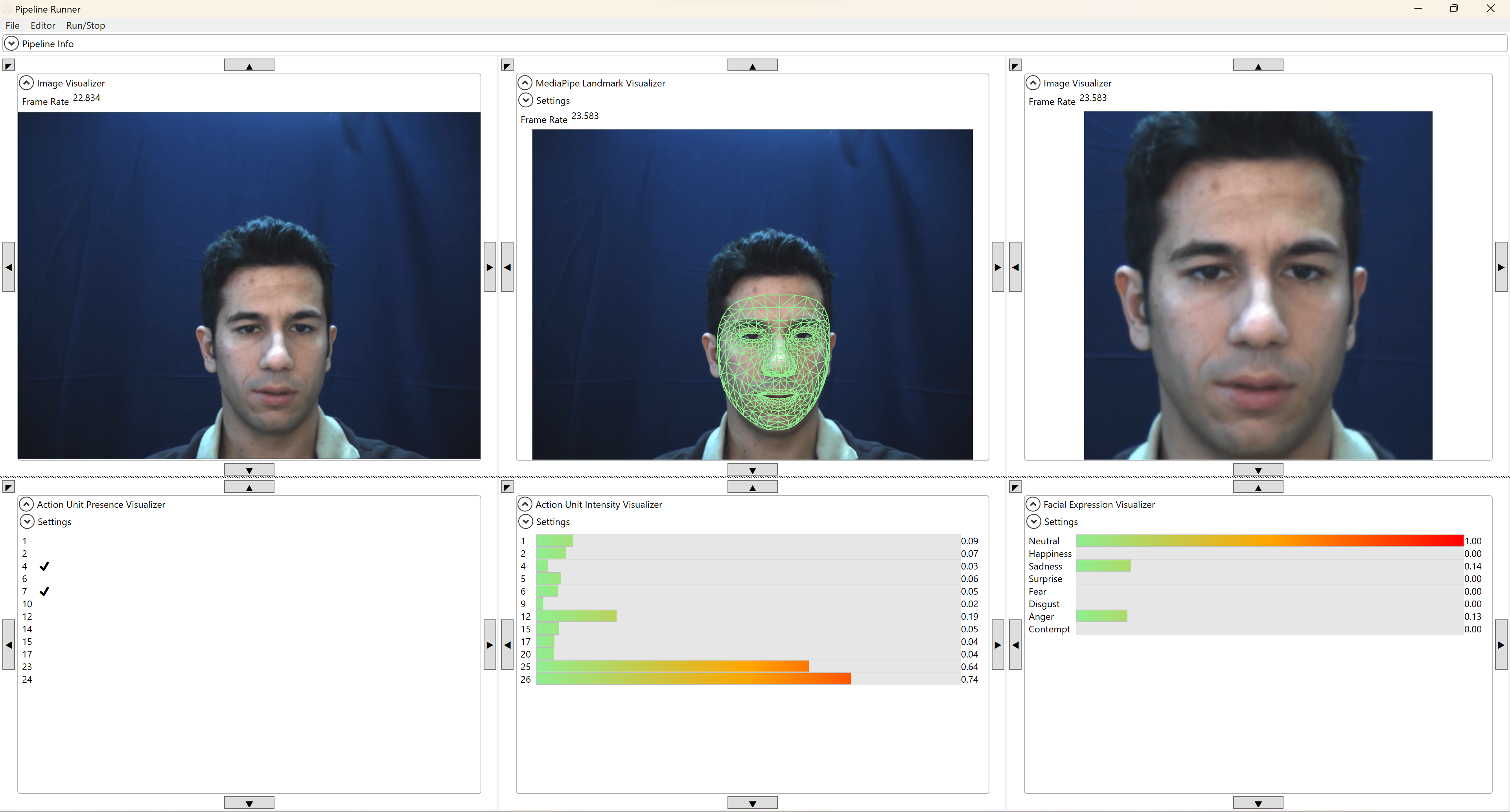
A full Face Analysis workshop in Python covers the following topic: - Create full web app from scratch using Gradio UI in Python - Processing Webcam input as Image and Video - Create Face Orientation on Face (Image/Video/Webcam) - Apply FaceDetect Algorithm - Apply FaceMesh (Image and Video) - Deploy full application to Hugging Face Space
https://github.com/prodramp/DeepWorks/tree/main/FaceProcessingWebcam
git clone https://github.com/prodramp/DeepWorks.git
cd DeepWorks/FaceProcessingWebcam/FaceAnalysisWebApp
conda create -n opencv_gradio python=3.8
conda activate opencv_gradio
pip install -r requirements.txt
建议所有环境配置问题直接问chatgpt比在网上找帖子排错高效。
然后继续在 PyCharm 中添加刚刚成功的Conda 环境opencv_gradio。

程序中不同版本gradio调用摄像头函数参数可能不同
如果安装的是gradio 4.39.0 原来程序的需要改为
webcam_image_in = gr.Image(label="Webcam Image Input")
webcam_video_in = gr.Video(label="Webcam Video Input")requirements.txt 需要改为旧版mediapipe
mediapipe==0.10.10
-
Students mustMark as done
提交到 https://classroom.github.com/a/ZEZxzkh6
修改gradio窗口布局,完成全部作业后发布公网链接让朋友试用。
https://docs.opencv.org/4.x/dc/d2c/tutorial_real_time_pose.html 参考上面链接,修改代码。实现gdut校徽,贴人头上。有AR透视变换(同态映射)变换效果。
增加一个模型 Torchlm人脸检测库 :https://github.com/DefTruth/torchlm 新建一个tab: “models comparison”页。 要求UI为4窗口:1原图视频,1个原视频上叠加mediapipe(或Dlib)68点, 1个叠加Torchlm 68点, 1个叠加2个模型的对应点连线(线的长度反应了2个模型的定位差异)
-
-
-
-
MoML: Online Meta Adaptation for 3D Human Motion Prediction https://openaccess.thecvf.com/content/CVPR2024/html/Sun_MoML_Online_Meta_Adaptation_for_3D_Human_Motion_Prediction_CVPR_2024_paper.html HeadGaS: Real-Time Animatable Head Avatars via 3D Gaussian Splatting https://arxiv.org/abs/2312.02902 GaussianEditor:Swift And Controllable 3D Editing With Gaussian Splatting https://openaccess.thecvf.com/content/CVPR2024/papers/Chen_GaussianEditor_Swift_and_Controllable_3D_Editing_with_Gaussian_Splatting_CVPR_2024_paper.pdf https://buaacyw.github.io/gaussian-editor
-
-
-
-
-
-
Students mustMark as done
提交到
https://classroom.github.com/a/p_pWDT3Z
git clone https://github.com/GDUTCV/ <作业页面自动生成的> .git
cd hw01_image_formation/code/
Create a new environment named lecturecv and install required packages (numpy, etc.) via running:
conda env create -f environment.yml
Note: A typical source of error is to use an old version of conda itself. You can update it via:
conda update -n base conda -c anaconda
Before launching your notebook you need to activate the environment:
conda activate lecturecv
Depending on your configuration, you might instead need to run:
source activate lecturecv
You can now start jupyter notebook from the directory:
jupyter-notebook
A browser window should be opened in which you can open the notebook of the first exercise called image_formation.ipynb
也可以上传到colab然后做编程题。
也可以上传到google drive再用colab打开,此时需要加载drive文件夹
from google.colab import drive
drive.mount('/content/drive')
-
HAHA: Highly Articulated Gaussian Human Avatars with Textured Mesh Prior https://arxiv.org/pdf/2404.01053 https://github.com/david-svitov/HAHA/ Emergent Correspondence from Image Diffusion https://proceedings.neurips.cc/paper_files/paper/2023/file/0503f5dce343a1d06d16ba103dd52db1-Paper-Conference.pdf https://diffusionfeatures. github.io Recurrent Partial Kernel Network for Efficient Optical Flow Estimation https://hmorimitsu.com/publication/2024-aaai-rpknet/2024-aaai-rpknet.pdf https://github.com/hmorimitsu/ptlflow
-
-
-
-
Students mustMark as done
1.作业2 提交到https://classroom.github.com/a/gzMZO0nH阅读 https://github.com/ahojnnes/local-feature-evaluation/blob/master/INSTRUCTIONS.md 并配置环境 准备数据
2.运行理解代码 scripts/matching_pipeline.m
3.运行理解代码
scripts/reconstruction_pipeline.py4. 可视化论文图片结果
-
-
-
-
-
Students mustMark as done
-
-
-
-
-
Students mustMark as done
阅读教材2第18章、 附录6、schoenberger_thesis的7 Structure-from-Motion Revisited
手写Bundle Adjustment对三维重建/SLAM研究的作用
-
Students mustMark as done
-
-
-
Students mustMark as done
-
-
10:00-11:20 Introduction to the tutorial and learning objectives. Overview of 3D body models, the history, mesh registration, linear blend skinning, SMPL and related models. Contents: history of body models, scanning, registration, PCA, linear blend skinning, corrective blend shapes, SMPL, faces, hands, SMPL-X, dynamics of soft tissue, future directions like implicit surfaces and neural rendering. Instructor: Michael Black
https://www.bilibili.com/video/BV1ysmtYjEYc/
11:20-11:40 Fitting SMPL to images using optimization. Instructor: Dimitrios Tzionas
https://www.bilibili.com/video/BV1Zom4YvEsy/
11:40-12:00 Regressing SMPL from images. Instructor: Timo Bolkart
-
Students mustMark as done
https://github.com/GDUTCV/homework-06
-
-
-
-
https://www.bilibili.com/video/BV1NyzuYGELa
Sun, D., Yang, X., Liu, M.-Y., Kautz, J., 2018. Pwc-net: Cnns for optical flow using pyramid, warping, and cost volume In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. pp. 8934–8943.
Sun, Deqing, et al. "Autoflow: Learning a better training set for optical flow." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021.
https://www.bilibili.com/video/BV1R9zvYcEsr
Teed, Z., Deng, J., 2020. Raft: Recurrent all-pairs field transforms for optical flow In: Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part II 16. Springer, pp. 402–419.
https://www.bilibili.com/video/BV1Ww4m117aY
Smith, C., Charatan, D., Tewari, A., & Sitzmann, V. (2024). FlowMap: High-Quality Camera Poses, Intrinsics, and Depth via Gradient Descent. arXiv preprint arXiv:2404.15259.
-
-
-
-
Students mustMark as done
https://3dgstutorial.github.io/index.html
3dgs cuda代码讲解 diff-gaussina-rasterization/cuda-rasterizer/forward.cu
41:41
-
-
Students mustMark as done
-
-
-
- 4DGS
- event camera
- 时空 transformer
de Blegiers, Tristan, et al. "EventTransAct: A video transformer-based framework for Event-camera based action recognition." 2023 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2023.
-
-